
Google’s TurboQuant: Scaling the “Memory Wall” for Large Language Models


As an AI Architect or Engineer in 2026, you know that managing infrastructure costs is just as hard as building the AI itself. Since the AI boom, we have been running into a massive physical limit called the “Memory Wall”.
At the ICLR 2026 conference, Google researchers presented TurboQuant, a breakthrough compression algorithm that effectively kills this bottleneck. By rethinking the geometry of AI memory, TurboQuant delivers a trifecta of performance gains previously thought impossible:
6x smaller memory footprint
8x faster processing speeds (measured on H100 GPUs against a JAX/PyTorch baseline)
Zero accuracy loss
The Background: How We Reached the “Memory Wall”
When a Large Language Model (LLM) generates text, it reads one word (or token) at a time. To keep track of the context and what has already been said, the model stores mathematical representations of previous words. This temporary storage is called the Key-Value (KV) Cache.
The Problem: The KV Cache grows linearly.
A 70B model’s weights take up about 140 GB.
But if you want a 1-million token context window, the KV cache alone can explode to over 320 GB — four times more than the actual model itself!
To fight this, engineers used “Quantization” (shaving off the decimal points of numbers to save space). But traditional quantization requires storing extra “scaling instructions” for every block of data to decode it later. This “efficiency tax” ate up all the memory savings. We were officially stuck at the memory wall.
Key Concepts: How TurboQuant optimises the memory
TurboQuant is what we call a “training-free” algorithm. This is a huge deal for developers because you don’t need to spend millions of dollars retraining your AI model. You simply “plug it in” to the inference engine, and it instantly shrinks the memory footprint by 6x without the AI losing its “intelligence”.
Vector Quantization (VQ): In standard AI, every word (token) is stored as a very long, precise decimal (like 0.82349152). This takes up a lot of “room” in the GPU memory.
The TurboQuant way: It rounds these long decimals into tiny 3-bit integers.
The Challenge: Normally, if you round a number that much, you lose the “nuance.” It’s like turning a high-definition 4K photo into low-resolution pixel art — you might lose the expression on a person’s face. TurboQuant finds a way to keep that expression intact.
2. Geometric Preconditioning: This is the secret sauce. In most AI data, you have “outliers” — random numbers that are much larger than others. These spikes make it impossible to compress the data evenly.
The TurboQuant way: Before it compresses anything, it performs a “Random Rotation.”
Simple Analogy: Imagine trying to pack a suitcase full of jagged rocks and flat clothes. It’s a mess. TurboQuant “scrambles” the data so that everything becomes a smooth, predictable shape — like turning those jagged rocks into fine sand. Once the data is “leveled” like a flat plain, it becomes incredibly easy to compress without losing the important bits.
TurboQuant’s secret sauce. It “scrambles” the data using a random rotationbefore compressing it. This makes the data distribution smooth and predictable, like turning a jagged mountain range into a flat plain
3. Unbiased Estimation:
Most compression “cheats” by losing some info. TurboQuant uses math to ensure that the _average_error is zero, meaning the AI’s “attention” stays perfectly sharp
It uses a mathematical trick to ensure that for every number it rounds up, another is rounded down in a way that the average error is exactly zero.
The Technical Know How
Standard data compression usually ruins AI. If you squeeze the KV cache too hard, you lose nuance, and the model starts hallucinating facts. TurboQuant fixes this using a method called “Data-Oblivious Compression”
Instead of analyzing the data to build a custom compression map, TurboQuant applies a random mathematical rotation to spread the information evenly. This turns messy, spiky data into a smooth, predictable structure that compresses perfectly every time.
The two core mechanisms powering this are:
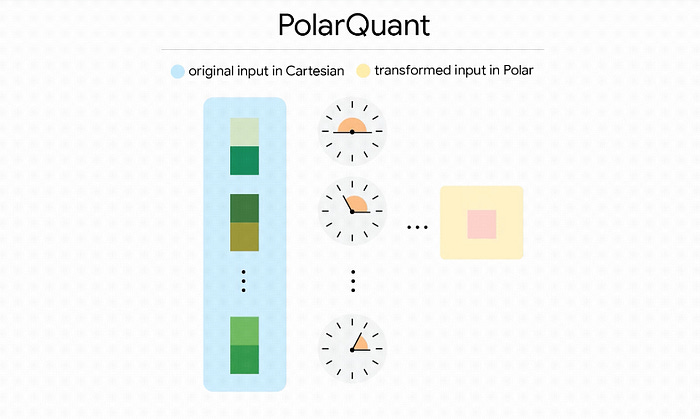
Polar Quant — Switching from “Blocks” to “Angles”:
Normally, your GPU stores vectors in standard Cartesian coordinates (X, Y, Z). The problem is that AI data often has massive “outliers” that break standard compression.
Polar Quant switches the system to Polar Coordinates, storing a radius (magnitude) and angles (direction). This smooths out the wild outliers, allowing the model to map everything onto a fixed grid without needing expensive memory-hogging normalization constants
TurboQuant’s first stage, PolarQuant, captures the primary Signal by switching to Polar coordinates.
Plain English Comparison: Instead of saying “Go 3 blocks East and 4 blocks North,” the model says “Go 5 blocks at a 37-degree angle.”
The Breakthrough: By focusing on the radius (signal strength) and the angle (direction of meaning), the model maps data onto a predictable circular grid.
Because the boundaries of a circle are constant, the model eliminates the need for “normalization constants” — the memory-heavy labels traditional methods must store for every block of data.
QJL (The 1-Bit Error Corrector):
After Polar Quant, a tiny bit of residual error is left over.
Even with great compression, tiny rounding errors can ruin an LLM’s “attention” span.
TurboQuant uses a technique called Quantized Johnson-Lindenstrauss (QJL) transform to take leftover errors and reduce them to a single sign bit (+1 or -1).
Think of it as a mathematical “spell-checker” that ensures the AI’s attention scores stay perfectly aligned with the original 32-bit data.
When the model calculates its attention scores, this 1-bit stage corrects the bias. This allows 3.5-bit compressed data to match the accuracy of the original 16-bit (FP16) model perfectly.
Experiments and results
Google’s research team put TurboQuant and PolarQuant through extensive testing using popular open-source models like Gemma and Mistral.
They evaluated the algorithms against rigorous long-context benchmarks, including LongBench, RULER, L-Eval, ZeroSCROLLS, and “Needle In A Haystack” (which tests a model’s ability to find one tiny fact hidden in a massive document).
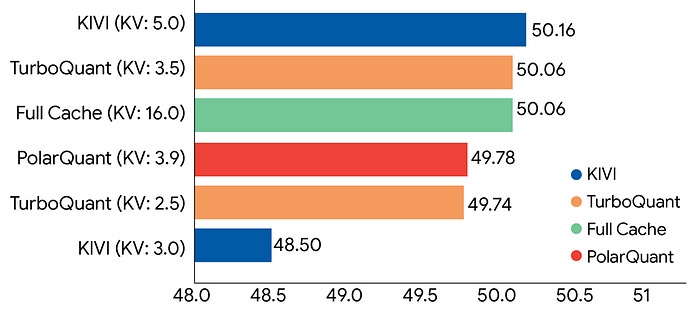
Across diverse tasks like code generation, summarization, and question-answering, TurboQuant consistently delivered top-tier accuracy. Notably, it successfully compressed the Key-Value (KV) cache down to just 3 bits without requiring any prior training or fine-tuning. This extreme compression shrank the memory footprint by a factor of at least 6x with absolutely no loss in model accuracy.
Beyond just saving space, TurboQuant is highly efficient to run; testing on NVIDIA H100 GPUs showed that operating at 4-bit precision actually accelerated attention computations by up to 8x compared to using standard 32-bit unquantized keys.
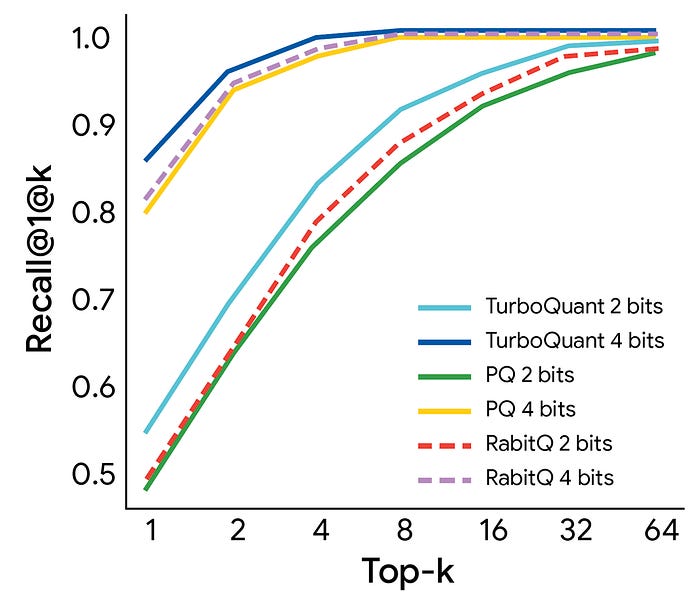
The team also tested TurboQuant for high-dimensional vector search applications. When compared to industry-standard methods (like PQ and RabbiQ), TurboQuant achieved noticeably superior retrieval accuracy. Because it does not rely on massive, inefficient codebooks or require dataset-specific calibration, it proved to be an incredibly fast and robust solution for building and querying large-scale search indexes.
Real-World Scenarios and Sector Impact
TurboQuant changes the economics of AI deployment by minimizing semantic distortion in memory-constrained environments:
Semantic Search Engines: Scale vector indices to billions of items with near-zero preprocessing time and near-optimal distortion.
Legal & Research: Process massive discovery sets on local, consumer-grade hardware while maintaining the precision required for factual retrieval.
Medical & Healthcare: Diagnostic AIs can process years of a patient’s medical history, lab results, and imaging notes in a single prompt window. *Local AI (Consumer Hardware): TurboQuant allows an NVIDIA RTX 4090 (24GB) — a gaming card — to run models that previously required a $30,000 H100**. This “democratizes” high-end AI.
What should an AI Developer look forward to?
As a developer or architect, the “Memory Wall” was your biggest budget-killer. With TurboQuant:
Stop Chunking, Start Prompting: You can move away from complex RAG (Retrieval) architectures and simply feed more data into the “Long Context” window.
Framework Integration: Look for TurboQuant to be integrated into engines like vLLM and TensorRT-LLM by mid-2026.
Economics: Expect the cost of “Long Context” API calls to drop by 70–80% as providers pack 6x more users onto the same hardware.
Community Integration Path:
HuggingFace: Use the
turboquantPython package as a drop-in replacement for standard KV caches.Llama.cpp: Utilize the
turboquant_plusfork for Metal/Apple Silicon optimizations.VLLM: Deploy via monkey-patch adapters for high-throughput serving environments.
Summary and References
TurboQuant marks a fundamental shift from “hacking” memory to rigorous algorithmic efficiency. By leveraging the geometry of polar coordinates and random rotations, it allows developers to scale past the Memory Wall and run long-context models on hardware previously deemed insufficient.
Reference Articles:
TurboQuant: Redefining AI efficiency with extreme compression https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate(https://arxiv.org/pdf/2504.19874)
Local AI just got a massive upgrade with TurboQuant (https://www.youtube.com/@pvergadia)
“Thank you for your time, and please feel free to suggest any other topic you’d be interested in reading an article about.”
You can show your support!
❤️ Like it
🤝 Send a LinkedIn connection request to stay in touch and discuss ideas.