
Nested Learning: The Illusion of “Deep” Learning

Link to the paper: NL.pdf
Imagine you are trying to learn a new language.
Method A: You study a dictionary for 10 years in a locked room. Then, you step out into the world. You know every word in that 10-year-old dictionary perfectly. But when someone uses new slang or a word coined yesterday, you freeze. You physically cannot add that new word to your brain.
Method B: You step out into the world immediately. You carry a small notebook. Every time you hear a new word, you scribble it down. Every night, you rewrite your notebook to organize it better. You are constantly updating your own “software.”
Method A is how almost all modern AI (like ChatGPT or Claude) works today.
Method B is what this new research paper, Nested Learning, proposes.
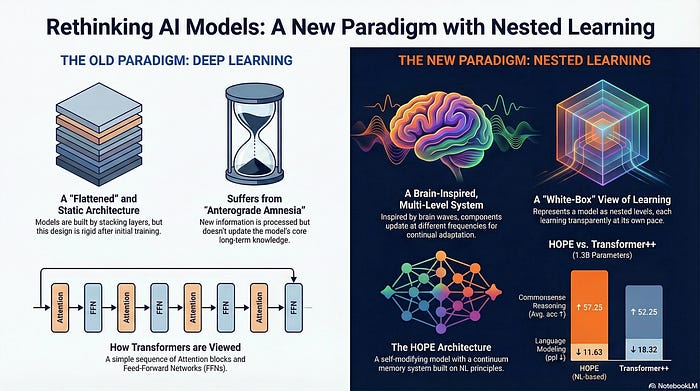
The paper argues that “Deep Learning” is an illusion. We think stacking more layers makes a model “deeper” and smarter, but it really just makes it a bigger calculator. True depth comes from Nested Loops — gears within gears that turn at different speeds to help the model learn forever.
The Current Ecosystem: The “Frozen Brain” Problem
Right now, the AI world is dominated by Transformers.
How they work: We take a massive neural network and train it on petabytes of data.
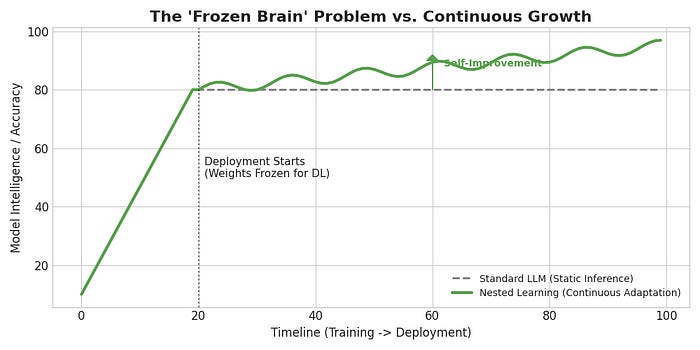
The Catch: Once the training is done, the model is frozen.
The Result: This leads to what the authors call “Anterograde Amnesia.” The model can remember everything from before 2023 (its training data), but it cannot form new long-term memories.
The Band-Aid: We try to fix this with “RAG” (looking up files) or “Context Windows” (pasting text into the prompt). But the model isn’t learning; it’s just reading your notes temporarily.
The New Paradigm: Nested Learning (NL)
The authors propose a radical shift: instead of viewing a model as a flat stack of layers, imagine it as a Russian Doll of Optimization Problems, or what the paper defines as a Continuum Memory System (CMS).
In this system, “weights” are no longer static numbers. They are Continuum Weights — parameters that live on a spectrum of time. Some weights are liquid (changing instantly), while others are solid (changing rarely).
Nested learning allows computational models that are composed of multiple (multi-layer) levels to learn from and process data with different levels of abstraction and time-scales.
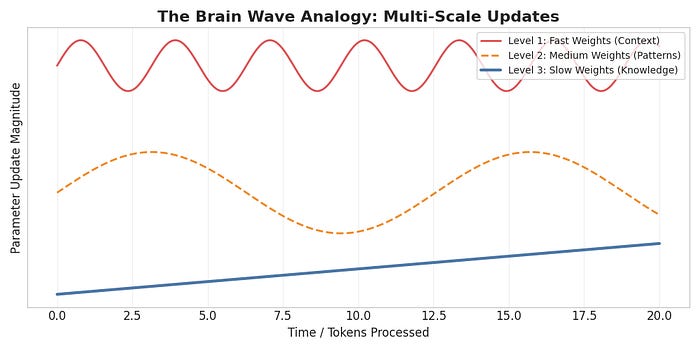
The Hierarchy: Fast, Mid, and Slow Learners
The HOPE architecture implements this by chaining multiple Neural Networks (MLPs), each assigned a specific “Frequency Rate” ($f$).
1. Fast-Level NN (The “Sprinter”)
Update Speed: Updates every single token (or very small chunks).
Role: Immediate Working Memory. It captures the exact phrasing of your current sentence or the variable definition you just wrote 5 seconds ago.
Mechanism: Uses a “Self-Modifying” recurrent loop where the optimizer itself is a small neural net predicting how to adjust weights instantly.
2. Mid-Level NN (The “Manager”)
Update Speed: Updates every $k$ steps (e.g., every 10–100 tokens).
Role: Contextual Adaptation. It notices patterns that span a few paragraphs, like “The user is asking about Python code, so I should bias towards programming syntax.”
Mechanism: Aggregates gradients over a short window before committing a change.
3. Slow-Level NN (The “Historian”)
Update Speed: Updates rarely (e.g., every 10,000 tokens) or remains frozen (Pre-trained).
Role: Core Knowledge. Stores immutable facts like “Gravity pulls down” or “Python keywords.”
Mechanism: Standard pre-training weights that provide the stable foundation the faster layers dance on top of.
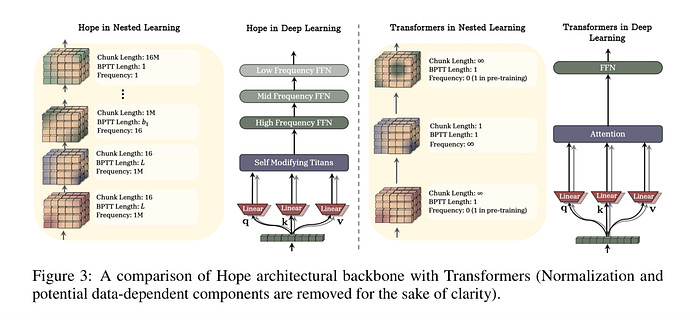
Deep Dive - HOPE: A Self-Referential Learning Module with Continuum Memory
Let’s look at how the “HOPE” architecture (proposed in the paper) compares to the standard Transformer.
The Flow of Intelligence: Static vs. Living Pipelines
1. Standard Deep Learning (The Rigid Pipe)
Concept: A straight, industrial pipe. Data flows through it, but the pipe itself never changes.
The Flaw: If the water (context) overflows the bucket (window), it spills and is lost forever. The pipe has “Amnesia.”
USER INPUT
│
▼
[ CONTEXT WINDOW BUCKET ] <-- Limited Size (e.g., 128k tokens)
│
│ (Batch of Tokens)
▼
===========================
║ FROZEN LAYER 1 ║ (Weights from 2023)
║ (Static Logic) ║
===========================
│
▼
===========================
║ FROZEN LAYER 2 ║ (No Updates Allowed)
║ (Static Logic) ║
===========================
│
▼
PREDICTION
│
x <-- NO FEEDBACK LOOP (Memory is lost after prediction)
2. Nested Learning (The Living Loop)
Concept: A biological system of pipes. As data flows through, it spins “turbines” (Optimizers) that physically reshape the pipe for the next drop of water.
The Fix: Memories are cycled back into the system. The pipe learns from the water.
USER INPUT
│
▼
[ CONTINUUM STREAM ]
│
├──> [ FAST PIPE (Level 1) ] <──────┐
│ │ (Updates in Milliseconds) │
│ │ “Memorizes: This Session” │
│ └─────────┬───────────────────┘
│ │ (Feedback Loop: Self-Correction)
│
├──> [ MID PIPE (Level 2) ] <───────┐
│ │ (Updates in Minutes) │
│ │ “Memorizes: User Habits” │
│ └─────────┬───────────────────┘
│ │ (Feedback Loop: Pattern Locking)
│
└──> [ SLOW PIPE (Level 3) ]
│ (Updates in Months)
│ “Memorizes: Core Language Facts”
│
▼
[ INTEGRATED PREDICTION ]
│
│
(Output becomes the new Input for the Loops)The “Brain Wave” Concept
The coolest part of the paper is how it mimics biology. Your brain doesn’t update every neuron every second.
High Frequency (Gamma): Rapid processing of what you are seeing right now.
Low Frequency (Delta): Slow consolidation of memories while you sleep.
Nested Learning builds this directly into the math.
Summary
“Deep Learning” gave us models that can read. “Nested Learning” might give us models that can grow.
By turning the architecture into a set of self-optimizing loops, we move from static encyclopedias to living, breathing intelligences.
“Thank you for your time, and please feel free to suggest any other topic you’d be interested in reading an article about.”
You can show your support!
❤️ Like it
🤝 Send a LinkedIn connection request to stay in touch and discuss ideas.
LLM | Transformers | Google | Agentic Ai | Machine Learning
Excellent analysis! What if this 'frozen brain' isuue extends beyond words to entire conceptual frameworks?